CLAP App
Published:
Context: this project was done as part of the Deep Learning course at IMT Atlantique. More details can be found here.
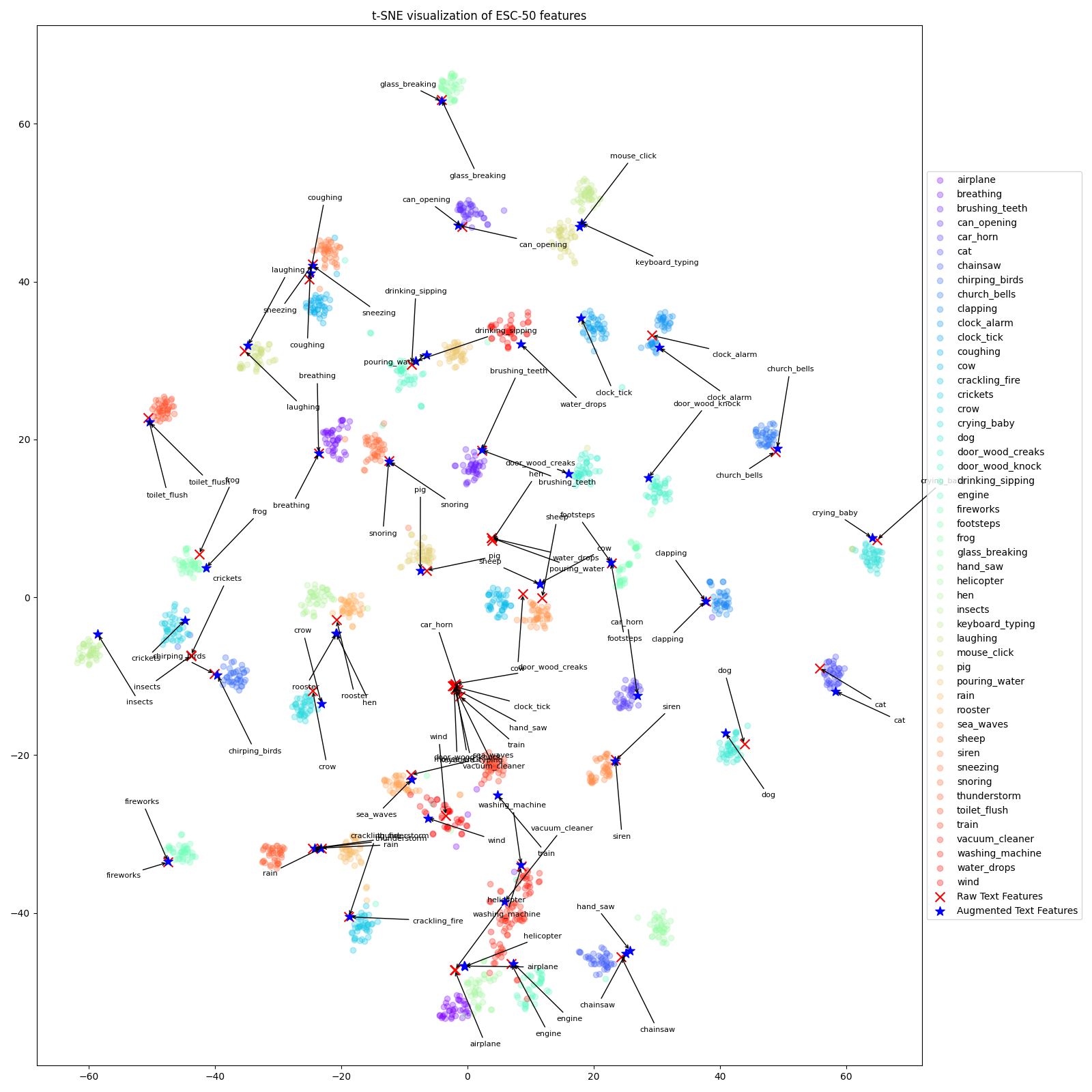
CLAP, or Contrastive Language-Audio Pretraining, is a pretraining strategy that learns a joint embedding space for text and audio. The model is trained to predict the audio representation from the text representation and vice versa. With this aligned representation space, we can perform text-prompted sound retrieval and zero-shot sound classification.
This also allows visual exploration of sound categories and their corresponding text prompts. The visualization below shows the embedding space of the CLAP model, where the points represent sounds. The colors indicate the sound categories, and the text prompts are also displayed. The embeddings are projected into a 2D space using t-SNE for visualization purposes. The dataset used is ESC-50.